Redis数据结构篇
Redis对象头结构体
一个RedisObject 对象头需要占据 16 字节的存储空间。
// redis 的对象头
typedef struct redisObject {
unsigned type:4; // 对象类型如 zset/set/hash 等等
unsigned encoding:4; // 对象编码如 ziplist/intset/skiplist 等等
unsigned lru:24; // 对象的「热度」,用于缓存淘汰
int refcount; // 引用计数,为零时,对象就会被销毁
void *ptr; // 8bytes,指针将指向对象内容 (body) 的具体存储位置
} robj;
字符串string
Redis 的字符串是动态可以修改的,内部结构实现上类似于 Java 的 ArrayList,是动态扩容的。在内存中它是以字节数组的形式存储。其结构为:
//类型T类似varint当字符串比较短时,可以是short,byte,int等
struct SDS<T> {
T capacity; // 数组容量
T len; // 数组长度
byte flags; // 特殊标识位
byte[] content; // 数组内容
}
Redis字符 SDS (Simple Dynamic String)
内存预分配,动态扩容。扩容策略:小于 1M 之前,扩容空间采用加倍,当长度超过 1M 每次扩容只会多分配 1M 大小的冗余空间。
字符串的两种存储方式embstr & raw
#smallstr为kkkkkk
127.0.0.1:6379[2]> debug object smallstr
Value at:0x7f2441947ca0 refcount:1 encoding:embstr serializedlength:7 lru:14567259 lru_seconds_idle:43
127.0.0.1:6379[2]> debug object bigstr
Value at:0x7f2441a57300 refcount:1 encoding:raw serializedlength:51 lru:14567278 lru_seconds_idle:37
embstr:用于存储对象(短的字符串),RedisObject 头和SDS存储在一起,内存连续,只需要一次内存申请。
raw:用于存储较大的字符串,RedisObject 头和分开SDS存储,需要两次内存申请。
内存分配器 jemalloc/tcmalloc 等分配内存大小的单位都是 2、4、8、16、32、64 等。为了存下一个字符串,至少需要申请一个32字节内存。占用空间小于64的通常用embstr,超过的用raw。
列表list
底层由链表实现,插入和删除时间复杂度为 O(1),查找时间O(n)。redis的链表也不是普通的链表,而是压缩列表ziplist和快速链表 quicklist。
为何不用普通的双向链表?
普通的双向链表prev 和 next 指针就要占去 16 个字节 (64bit 系统的指针是 8 个字节),另外每个节点的内存都是单独分配,会加剧内存的碎片化,影响内存管理效率。
在列表元素较少的情况下会使用一块连续的内存存储,这个结构是 ziplist,也即是压缩列表。它将所有的元素紧挨着一起存储,分配的是一块连续的内存。当数据量比较多的时候才会改成 quicklist。
ziplist
Redis 为了节约内存空间使用,zset 和 hash 容器对象在元素个数较少的时候,采用压缩列表 (ziplist) 进行存储。压缩列表是一块连续的内存空间,元素之间紧挨着存储,没有任何冗余空隙。
struct ziplist<T> {
int32 zlbytes; // 整个压缩列表占用字节数
int32 zltail_offset; // 最后一个元素距离压缩列表起始位置的偏移量,为了支持双向遍历
int16 zllength; // 元素个数
T[] entries; // 元素内容列表,挨个挨个紧凑存储
int8 zlend; // 标志压缩列表的结束,值恒为 0xFF
}
如图
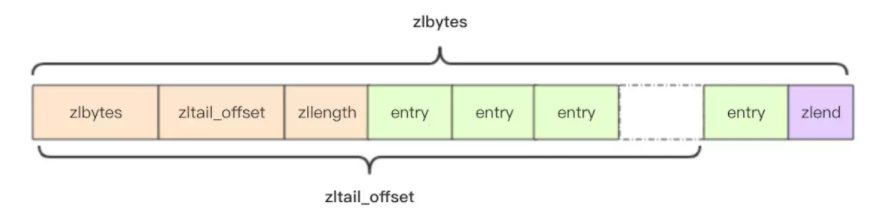
因为 ziplist 都是紧凑存储,没有冗余空间,插入一个新的元素就需要调用 realloc 扩展内存。realloc 会重新分配新的内存空间,并将之前的内容一次性拷贝到新的地址。如果 ziplist 占据内存太大,重新分配内存和拷贝内存就会有很大的消耗。所以 ziplist 不适合存储大型字符串,存储的元素也不宜过多。
quicklist
quicklist 是 ziplist 和 linkedlist 的混合体,它将 linkedlist 按段切分,每一段使用 ziplist 来紧凑存储,多个 ziplist 之间使用双向指针串接起来。如图
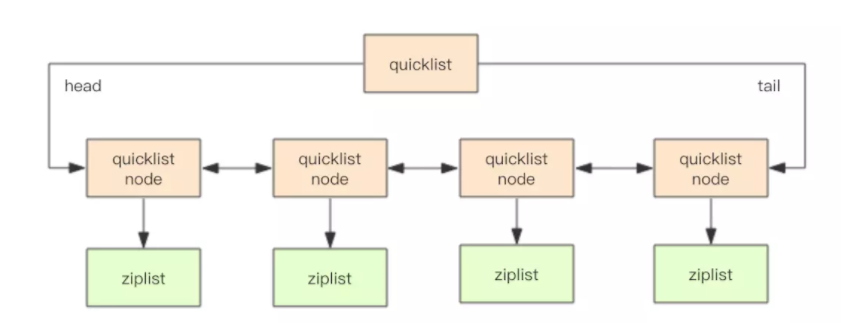
quicklist 内部默认单个 ziplist 长度为 8k 字节,超出了这个字节数,就会新起一个 ziplist。还会对 ziplist 进行压缩存储。
127.0.0.1:6379> debug object list:py_list
Value at:0x7f244385eff0 refcount:1 encoding:quicklist serializedlength:181671 lru:14570593 lru_seconds_idle:21 ql_nodes:78 ql_avg_node:326.92 ql_ziplist_max:-2 ql_compressed:0 ql_uncompressed_size:632748
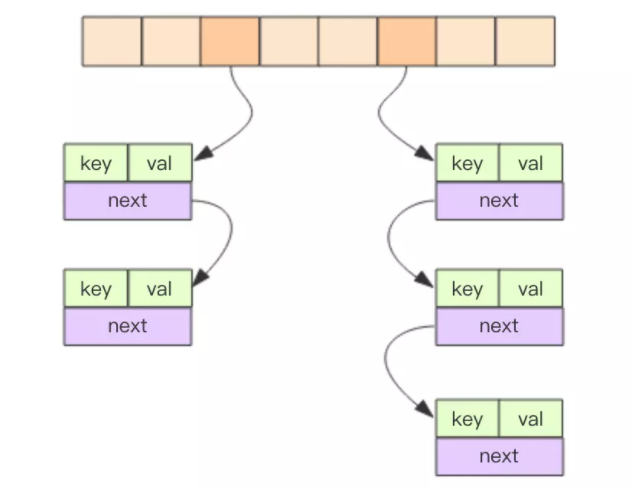
字典hash
Redis 所有 key 和 value 也组成了一个全局字典
key无序,不重复,根据key来O(1)快速查找。链表法解决hash冲突。扩容时,减少卡顿采用了渐进式 rehash 策略。
hash结构,第一维是数组,第二维是链表。数组中存储的是第二维链表的第一个元素的指针。
渐进式 rehash
rehash 的同时,保留新旧两个 hash 结构,查询时会同时查询两个 hash 结构,循序渐进地将旧 hash 的内容一点点迁移到新的 hash 结构中。
hash 函数
哈希函数,数据分布是否均匀对性能影响很大。Redis 的字典默认的 hash 函数是 siphash。siphash 算法即使在输入 key 很小的情况下,也可以产生随机性特别好的输出,而且它的性能也非常突出。
set 的结构底层实现也是字典,只不过所有的 value 都是 NULL,其它的特性和字典一模一样。不少编程语言的set也是基于hash实现的。
集合set
它的内部实现相当于一个特殊的字典,字典中所有的 value 都是一个值NULL。
127.0.0.1:6379[2]> smembers src1
1) "value2"
2) "value3"
3) "value1"
127.0.0.1:6379[2]> debug object src1
Value at:0x7f2441a57320 refcount:1 encoding:hashtable serializedlength:22 lru:14580069 lru_seconds_idle:20
set 集合容纳的元素都是整数并且元素个数较小时,Redis 会使用 intset 来存储结合元素。intset 是紧凑的数组结构,同时支持 16 位、32 位和 64 位整数。
struct intset<T> {
int32 encoding; // 决定整数位宽是 16 位、32 位还是 64 位
int32 length; // 元素个数
int<T> contents; // 整数数组,可以是 16 位、32 位和 64 位
}

有序集合zset
有序集合是集合,value唯一,通过score排序。 zset 要支持随机的插入和删除,且需要score有序。插入新元素还需定位到合适的score位置。
有序集合综合使用了hash和skiplist数据结构。用hash 结构来存储 value 和 score 的对应关系。
思考:需要插入删除,数组实现需要搬移数据,麻烦。需要快速查找,有序数组二分查找到是可以,但不满足快速插入删除。需要同时支持,快速查找,删除,插入的,跳跃表的确是个好选择。 那为何不能是B+树或其他查找树呢,相比B+树,跳跃表在这里的优势是什么呢?
跳跃列表
跳跃表可以理解为是在普通链表的基础上加了多级索引,从而实现快速定位。

Redis 的跳跃表共有 64 层,每一个 kv 块对应的结构如下面的代码中的zslnode结构,kv 之间使用指针串起来形成了双向链表结构,它们是 有序 排列的,从小到大。同一层的 kv 会使用指针串起来。每一个层元素的遍历都是从 kv header 出发。
struct zslnode {
string value;
double score;
zslnode*[] forwards; // 多层连接指针
zslnode* backward; // 回溯指针
}
struct zsl {
zslnode* header; // 跳跃列表头指针
int maxLevel; // 跳跃列表当前的最高层
map<string, zslnode*> ht; // hash 结构的所有键值对
}
跳跃表搜索过程从head高层,就像下楼梯一样搜索。
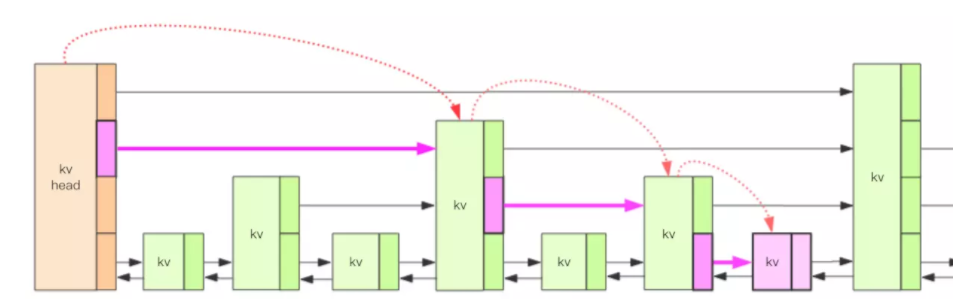
元素排名是怎么算出来的?
Redis 在 skiplist 的 forward 指针上进行了优化,给每一个 forward 指针都增加了 span 属性,span 是「跨度」的意思,表示从前一个节点沿着当前层的 forward 指针跳到当前这个节点中间会跳过多少个节点。Redis 在插入删除操作时会小心翼翼地更新 span 值的大小。
跳跃表实现参照算法与数据结构那里。
参考:Redis 深度历险:核心原理与应用实践